 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausalGuard: Conformal Inference under Graph Uncertainty
May 21, 2026Estimating treatment effects from observational data requires choosing an adjustment set, but valid adjustment depends on an unknown causal graph. Graph misspecification can cause under-coverage, while graph-agnostic conformal wrappers may regain nominal coverage only through large padding. We introduce CausalGuard, a structure-weighted conformal framework that calibrates after aggregating graph-conditional doubly robust pseudo-outcomes. Candidate DAGs are proposed from an LLM-derived edge prior, pruned by conditional-independence tests, and reweighted by Bayesian Information Criterion. A composite nonconformity score then calibrates the posterior-weighted pseudo-outcome. CausalGuard provides distribution-free finite-sample marginal coverage for this aggregated pseudo-outcome; under causal identification, overlap, conditional-mean nuisance stability, and concentration on target-aligned valid adjustment strategies, its conditional mean converges to the true Conditional Average Treatment Effect. Across five benchmarks, CausalGuard attains mean coverage above the nominal 90% level for the directly evaluable target and reduces width when graph-agnostic conformal baselines require large padding. Stress tests show that CausalGuard suppresses invalid collider adjustment and remains stable under misspecified priors when the retained candidate set is data-supported.
Who Gets Flagged? The Pluralistic Evaluation Gap in AI Content Watermarking
Apr 15, 2026Watermarking is becoming the default mechanism for AI content authentication, with governance policies and frameworks referencing it as infrastructure for content provenance. Yet across text, image, and audio modalities, watermark signal strength, detectability, and robustness depend on statistical properties of the content itself, properties that vary systematically across languages, cultural visual traditions, and demographic groups. We examine how this content dependence creates modality-specific pathways to bias. Reviewing the major watermarking benchmarks across modalities, we find that, with one exception, none report performance across languages, cultural content types, or population groups. To address this, we propose three concrete evaluation dimensions for pluralistic watermark benchmarking: cross-lingual detection parity, culturally diverse content coverage, and demographic disaggregation of detection metrics. We connect these to the governance frameworks currently mandating watermarking deployment and show that watermarking is held to a lower fairness standard than the generative systems it is meant to govern. Our position is that evaluation must precede deployment, and that the same bias auditing requirements applied to AI models should extend to the verification layer.
Quantifying Memorization and Privacy Risks in Genomic Language Models
Mar 09, 2026Genomic language models (GLMs) have emerged as powerful tools for learning representations of DNA sequences, enabling advances in variant prediction, regulatory element identification, and cross-task transfer learning. However, as these models are increasingly trained or fine-tuned on sensitive genomic cohorts, they risk memorizing specific sequences from their training data, raising serious concerns around privacy, data leakage, and regulatory compliance. Despite growing awareness of memorization risks in general-purpose language models, little systematic evaluation exists for these risks in the genomic domain, where data exhibit unique properties such as a fixed nucleotide alphabet, strong biological structure, and individual identifiability. We present a comprehensive, multi-vector privacy evaluation framework designed to quantify memorization risks in GLMs. Our approach integrates three complementary risk assessment methodologies: perplexity-based detection, canary sequence extraction, and membership inference. These are combined into a unified evaluation pipeline that produces a worst-case memorization risk score. To enable controlled evaluation, we plant canary sequences at varying repetition rates into both synthetic and real genomic datasets, allowing precise quantification of how repetition and training dynamics influence memorization. We evaluate our framework across multiple GLM architectures, examining the relationship between sequence repetition, model capacity, and memorization risk. Our results establish that GLMs exhibit measurable memorization and that the degree of memorization varies across architectures and training regimes. These findings reveal that no single attack vector captures the full scope of memorization risk, underscoring the need for multi-vector privacy auditing as a standard practice for genomic AI systems.
Authenticated Contradictions from Desynchronized Provenance and Watermarking
Mar 02, 2026Cryptographic provenance standards such as C2PA and invisible watermarking are positioned as complementary defenses for content authentication, yet the two verification layers are technically independent: neither conditions on the output of the other. This work formalizes and empirically demonstrates the $\textit{Integrity Clash}$, a condition in which a digital asset carries a cryptographically valid C2PA manifest asserting human authorship while its pixels simultaneously carry a watermark identifying it as AI-generated, with both signals passing their respective verification checks in isolation. We construct metadata washing workflows that produce these authenticated fakes through standard editing pipelines, requiring no cryptographic compromise, only the semantic omission of a single assertion field permitted by the current C2PA specification. To close this gap, we propose a cross-layer audit protocol that jointly evaluates provenance metadata and watermark detection status, achieving 100% classification accuracy across 3,500 test images spanning four conflict-matrix states and three realistic perturbation conditions. Our results demonstrate that the gap between these verification layers is unnecessary and technically straightforward to close.
ZKPROV: A Zero-Knowledge Approach to Dataset Provenance for Large Language Models
Jun 26, 2025As the deployment of large language models (LLMs) grows in sensitive domains, ensuring the integrity of their computational provenance becomes a critical challenge, particularly in regulated sectors such as healthcare, where strict requirements are applied in dataset usage. We introduce ZKPROV, a novel cryptographic framework that enables zero-knowledge proofs of LLM provenance. It allows users to verify that a model is trained on a reliable dataset without revealing sensitive information about it or its parameters. Unlike prior approaches that focus on complete verification of the training process (incurring significant computational cost) or depend on trusted execution environments, ZKPROV offers a distinct balance. Our method cryptographically binds a trained model to its authorized training dataset(s) through zero-knowledge proofs while avoiding proof of every training step. By leveraging dataset-signed metadata and compact model parameter commitments, ZKPROV provides sound and privacy-preserving assurances that the result of the LLM is derived from a model trained on the claimed authorized and relevant dataset. Experimental results demonstrate the efficiency and scalability of the ZKPROV in generating this proof and verifying it, achieving a practical solution for real-world deployments. We also provide formal security guarantees, proving that our approach preserves dataset confidentiality while ensuring trustworthy dataset provenance.
The Feasibility of Topic-Based Watermarking on Academic Peer Reviews
May 27, 2025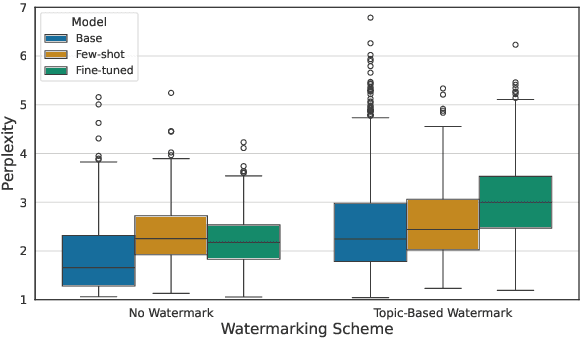



Large language models (LLMs) are increasingly integrated into academic workflows, with many conferences and journals permitting their use for tasks such as language refinement and literature summarization. However, their use in peer review remains prohibited due to concerns around confidentiality breaches, hallucinated content, and inconsistent evaluations. As LLM-generated text becomes more indistinguishable from human writing, there is a growing need for reliable attribution mechanisms to preserve the integrity of the review process. In this work, we evaluate topic-based watermarking (TBW), a lightweight, semantic-aware technique designed to embed detectable signals into LLM-generated text. We conduct a comprehensive assessment across multiple LLM configurations, including base, few-shot, and fine-tuned variants, using authentic peer review data from academic conferences. Our results show that TBW maintains review quality relative to non-watermarked outputs, while demonstrating strong robustness to paraphrasing-based evasion. These findings highlight the viability of TBW as a minimally intrusive and practical solution for enforcing LLM usage in peer review.
Topic-based Watermarks for LLM-Generated Text
Apr 02, 2024



Recent advancements of large language models (LLMs) have resulted in indistinguishable text outputs comparable to human-generated text. Watermarking algorithms are potential tools that offer a way to differentiate between LLM- and human-generated text by embedding detectable signatures within LLM-generated output. However, current watermarking schemes lack robustness against known attacks against watermarking algorithms. In addition, they are impractical considering an LLM generates tens of thousands of text outputs per day and the watermarking algorithm needs to memorize each output it generates for the detection to work. In this work, focusing on the limitations of current watermarking schemes, we propose the concept of a "topic-based watermarking algorithm" for LLMs. The proposed algorithm determines how to generate tokens for the watermarked LLM output based on extracted topics of an input prompt or the output of a non-watermarked LLM. Inspired from previous work, we propose using a pair of lists (that are generated based on the specified extracted topic(s)) that specify certain tokens to be included or excluded while generating the watermarked output of the LLM. Using the proposed watermarking algorithm, we show the practicality of a watermark detection algorithm. Furthermore, we discuss a wide range of attacks that can emerge against watermarking algorithms for LLMs and the benefit of the proposed watermarking scheme for the feasibility of modeling a potential attacker considering its benefit vs. loss.